
Een kennismaking met Data Science
Data Science, Artificial Intelligence en Machine Learning zijn termen die je misschien al eerder hebt gehoord. Grote en kleine bedrijven die gebruik maken van data science hebben vaak te maken met het ’bandwagon-effect’. Hoewel de stimulans er is, ontbreekt de fundamentele kennis vaak om het daadwerkelijk uit te voeren. In deze kennismaking met Data Science leer je alles over de basis en ontdek je waarom data science geen magie is!
De basis: data
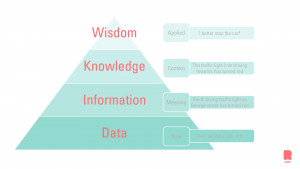
Data zonder context is slechts gebrabbel, net zoals het woord ‘rood’ geen vaste betekenis heeft, behalve dat het een kleur is. Maar als we het in context plaatsen, bijvoorbeeld “de kleur van het verkeerslicht is rood”, kun je die informatie gebruiken om te anticiperen op je volgende acties. Daarnaast kun je de DIKW (Data Information Knowledge and Wisdom) piramide gebruiken om data in context te plaatsen.
Wat is data science?
Aangezien dit blog een kennismaking met data science is, beginnen we bij de basis. Bij data science gebruik je data en geef je betekenis aan de data. Met andere woorden: data omzetten in informatie (Data Information). Deze transformatie kan gedaan worden door data te visualiseren. De processen waarin de data gebruikt wordt te leren kennen en de metadata te begrijpen. Bovendien wordt de informatie getransformeerd naar kennis (Knowledge) wanneer je de context aanlevert. Als alle kaarten eenmaal op tafel liggen, kunnen we plannen maken voor actie: wijsheid (Wisdom)!
Wijsheid is waar we onze kennis zo goed mogelijk toepassen. Data scientists rapporteren hun bevindingen meestal met een aanbeveling aan het management. De DIKW-piramide is de basis van de gegevenstransformatie. Elke data scientist of machine learning engineer doorloopt dit proces expliciet of impliciet.
Data science & data mining
Nu we weten welke cyclus de gegevens doorlopen, kunnen we gaan kijken naar data mining. Data mining is een vakgebied in de data science dat zich bezighoudt met het ophalen van gegevens en het maken van voorspellingen. Deze definitie is een nuancering omdat het veel verschillende onderdelen omvat, maar omdat deze blog een kennismaking met data science is, houden we het simpel. Ook zijn deze definities niet in steen gebeiteld en variëren ze van tijd tot tijd en van persoon tot persoon. Daarom gebruiken we data mining technieken om te voorspellen wat er gaat gebeuren, gebaseerd op oude gegevens. Met andere woorden: we trainen modellen met oude data om te voorspellen wat nieuwe data zal doen. We behandelen twee technieken van data mining in deze blog serie: supervised en unsupervised learning.
Supervised learning
Wat is supervised learning?
Supervised learning betekent dat we zowel de kenmerken als het antwoord op de vraag hebben. Net zoals we een kind het verschil leren tussen een hond en een kat, leren we het model dit onderscheid te maken op een vergelijkbare manier. De volgende afbeelding toont de kenmerken van een hond en een kat. De kenmerken die het dier beschrijven worden ‘variabelen’ genoemd. Deze variabelen beschrijven een dier, namelijk een hond of een kat. Hetgeen dat door de variabelen wordt beschreven, wordt de ‘class’ of ‘target’ variabel genoemd. Het totaal aantal variabelen noemen we de dimensionaliteit van de dataset. Hoe meer variabelen je hebt, hoe meer informatie je hebt om een voorspelling te maken. Let wel op: té veel variabelen in een model kunnen een averechts effect hebben.
Het model vertelt ons zijn voorspelling op basis van de geselecteerde variabelen. Omdat het model getraind wordt op historische data, kunnen wij checken of het model een goede voorspelling heeft gemaakt. Zo niet, dan passen we het model aan en vertellen we hem welke andere selectie van variabelen gebruikt moet worden. Deze manier van werken is het uitgangspunt van supervised learning in een notendop.
Als je op zoek bent naar een Data Science en Machine Learning oplossing, dan is Gartner’s Magic Quadrant een waardevolle bron.
Unsupervised learning
Wat is unsupervised learning?
Unsupervised learning betekent dat we het antwoord op de vraag niet van te voren weten (d.w.z. dat we geen target variabele hebben), maar we leiden het antwoord af door de variabelen te vergelijken. Wanneer we op een sociaal evenement zijn, kunnen er groepen gevormd worden. We kunnen de kenmerken van de mensen gebruiken om te zien tot welke groep ze behoren. We kunnen de mensen dan labelen met bijvoorbeeld gekleurde shirts. De shirts vertegenwoordigen de target variabele, namelijk bij welke groep ze horen. Als er nieuwe kenmerken (variabelen) ontstaan, kunnen we nog steeds zien wie tot welke groep behoort. Dat is de kern van unsupervised learning.
Er zijn meerdere methoden, zoals ‘semi-supervised learning’ of ‘reinforcement learning’. Nu je in deze kennismaking met data science alles hebt geleerd over de basis en de fundamenten, willen we dat je zelf een sprong in het diepe waagt!

Gerelateerde berichten

Welkom artificiële intelligentie
In dit interview spreekt Jonathan Aardema met prof. Eric Postma (hoogleraar Cognitive Science and Artificial Intelligence aan de Universiteit van Tilburg) over het waarom, hoe en wat van artificial intelligence applicaties. Wat zien we in de praktijk en wat zegt de wetenschap erover?

Gartner Magic Quadrant for Business Intelligence Platforms and Analytics 2020
Het Gartner Magic Quadrant for Business Intelligence is een analistenrapport waar we elk jaar naar uitkijken. Zowel de diepte als de reikwijdte van dit onderzoek maken het de moeite waard om te lezen. Maar niet veel mensen nemen de tijd om echt in de details van het rapport te graven.

Klantverloop verminderen door gebruik van data science
Het verminderen van klantverloop (customer churn) is één van de topprioriteiten van bedrijven. Nu hoor ik je denken: wat hebben data science en machine learning hiermee te maken? In deze blog vertellen we je hoe je klantverloop kunt verminderen met behulp van data science.